Protect critical data environments on Earth with a solution successfully tested in space

Learn about a successful experiment aboard the International Space Station simulating a compute failure and successfully recovering from it with no data or transaction loss in under 30 seconds.
We all have experienced the frustration of downtime in our private lives: a favorite app isn’t working, you can’t order a gift because the website isn’t responding, you can’t make an urgent flight booking. When it comes to businesses, the impact of downtime goes beyond lost revenue. The costs of losing valuable data, recovering from an outage and reputational impact are high and rising. In a prior post we shared how for many companies, avoiding even one downtime event can quickly repay the small cost of an effective high availability (HA) and disaster recovery (DR) solution.
Let us imagine an outage on space, not on Earth; the consequences of downtime could be catastrophic. Fortunately in HPE we have a solution that helps prevent downtime, both on Earth and space: HPE Serviceguard for Linux (SGLX) maximizes application availability by continuously monitoring the health of your infrastructure including hardware, operating system, virtualization, storage, network, application, and any other parameter that may impact the functioning of applications. When a failure is detected, SGLX automatically and transparently ensures that normal operations are resumed in mere seconds, on a healthy node.
SGLX has been protecting mission critical environments for decades, and as further proof of its robustness and resiliency, the solution has just been successfully tested in the harsh conditions of space, as part of the HPE Spaceborne project.
Another Spaceborne milestone is completed
Spaceborne is a years-long collaborative effort between HPE and NASA, where key technologies are tested to see how they withstand the tough conditions of space. In May of this year the Spaceborne Computer-2 successfully powered up on the International Space Station (ISS) to emulate a computational load. In October, we completed the latest milestone in this exciting journey: An experiment involving simulating a compute failure in the Spaceborne Computer-2 environment and seamlessly and rapidly recovering the impacted application from it—within only 30 seconds—leveraging HPE Serviceguard for Linux.
Environment setup
The Spaceborne Computer-2 consists of HPE ProLiant DL360 servers and HPE Edgeline Converged Edge systems. For the failover experiment we leveraged two HPE ProLiant DL360 servers with Red Hat Enterprise Linux as the operating system to form a cluster with two nodes: one of them acting as the primary node and the other as the hot standby node, ready to take over in case of any failure.
We ran this experiment in three environments: A Test and Development system, a Production system located on Earth in NASA premises, and a Production system located on space aboard the International Space Station. These three environments were configured in the exact same way.
30 seconds to recover from a compute failure in space
Because of the special Spaceborne set up in space with a small footprint and no access to shared storage or SAN infrastructure, we chose a Microsoft SQL Server application running on Availability Group deployment mode as the test application. In this way, we would be able to test an enterprise-grade application with no requirement for shared storage due to its in-built replication technology.
A highly available (HA) HPE Serviceguard for Linux (SGLX) cluster was created once the application installation was completed on the ProLiant DL360 server pair. One server acted as the primary node and the other as a hot standby node ready to take over upon any failure. Clustering with SGLX ensures that all resources required to run the application are constantly monitored for failures.
SGLX quorum sever software was also installed in one the Edgeline servers, playing an arbitrator or tie-breaker role in case of a network breakage or partition between the two nodes.
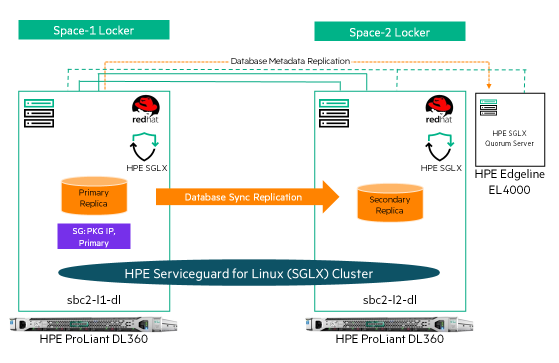
Once the SGLX cluster was set up, the primary and standby nodes of the database were configured to have a table simulating an “Inventory” application. As database transactions started, a failure to the application was induced. At that point, Serviceguard for Linux was able to detect the failure. A failover was initiated to the secondary node which promoted it as the new primary, successfully recovering from the failure and resuming operations without any data or transaction loss in under 30 seconds!
Following this, the recovery failback simulation was also completed, meaning inducing another failure in the new primary node, failing over to the healthy node and reverting back operations to the original primary node. This simulation was also completed in just under half a minute.
It’s worth mentioning that the experiment was first completed in the test system, then performed on Earth in NASA premises, and finally aboard the ISS.
A battled-hardened solution, now tested on space
What did we learn from this experiment? Anyone knows that failures happen, no matter whether on Earth or space. When they do, you want a robust solution that helps you recover rapidly and predictably so you can resume normal operations as soon as possible. The results of this experiment are proof that Serviceguard for Linux is a resilient solution that you can trust to protect your critical data workloads. We tested an enterprise-grade application requiring high performance and the results speak for themselves: 30 seconds to identify the failure and recover smoothly and with no data or transaction loss.
But this is not all. When planning for this experiment we had to consider a series of hardware constrains in the environment due to the small footprint available aboard the ISS. This meant no shared storage and no traditional SAN were available. Therefore we chose an application with built-in replication capabilities that didn’t require access to shared storage or a SAN. However, if we were repeating the experiment today, we could choose any application (such as SAP HANA using system replication, Oracle using Data Guard or any other application without replication capabilities), due to the recently introduced SGLX Flex Storage Add-On capability. With Flex Storage, you can deploy SGLX on any kind of storage architecture—including persistent memory, local/direct-attached/disaggregated storage, and HCI. To learn more about the Flex Storage Add-on you can read this blog.
Say “no” to downtime and get started with Serviceguard for Linux – a solution now tested on space– by talking to your HPE representative.
To learn more, check out the resources below:
Meet HPE blogger Diana Cortes, Marketing Manager, HPE Data Solutions
Diana has spent the past 23 years working with the technologies that power the world’s most demanding IT environments and is interested in how solutions based on those technologies impact the business. A native from Colombia, Diana holds an MBA from Georgetown University and has held a variety of regional and global roles with HPE in the US, the UK and Sweden. She is based in Stockholm, Sweden.
Compute Experts
Hewlett Packard Enterprise
twitter.com/hpe_compute
linkedin.com/showcase/hpe-servers-and-systems/
hpe.com/servers
Back