Technical deep dive: HPE GreenLake for Block Storage built on HPE Alletra Storage MP
Technical deep dive: HPE GreenLake for Block Storage built on HPE Alletra Storage MP
StorageExperts
2 weeks ago
Take a closer look at the new hardware and software powering the industry’s first disaggregated, scale-out block storage service with a 100% data availability guarantee.*
–By Dimitris Krekoukias, Distinguished Technologist, HPE

There’s the adage that variety is the spice of life, but, as usual, too much of anything can be a challenge. Take, for example, storage hardware at any company that has multiple storage portfolio offerings.
Almost always, the hardware of various offerings differs – often substantially – and not just in performance or capacity, but also in quality and reliability. In many cases, the hardware is so dramatically different that there can be absolutely no sharing – the drives are different, the controllers are different, the chassis is different, one so on.
At HPE, we have a different approach. We’re taking major steps to standardize storage solution hardware to provide a better customer experience.
HPE Alletra Storage MP: a common hardware platform for HPE Storage
A common underlying hardware platform for storage? That’s no small feat. It’s also something unique in the storage industry.
When designing the standardized HPE Alletra Storage MP platform, we wanted to ensure it would be suitable for multiple kinds of applications, now and in the future. That means running block, file, and object workloads – at any scale – using the exact same set of building blocks.
We wanted to use common hardware as much as possible, and not have to rely on custom ASICs or media. All the supply chain issues companies have faced over the past few years have been more than enough trouble for everyone, and custom hardware causes extra challenges.
Upgradability between generations was also extremely important, as was coexistence of different generations. And the ability to start small and scale to crazy big was essential.
To accomplish our goal, the quality of the HPE Alletra Storage MP hardware had to be uniform. We would use the same high-end hardware for both the ultra-fast versions of Tier-0 platforms with 100% data availability guarantees as well as the entry-level versions, and everything in between. If the only difference is performance and capacity, there is no need to sacrifice any reliability for the less expensive offerings. Some details:
-
A plethora of PCIe lanes, huge memory throughput, and high core density are important for performance: we standardized on AMD CPUs for the new hardware.
-
Low-power consumption and a tighter footprint are also very important and help with sustainability efforts, so we used extremely efficient components all around, as well as OCP-format expansion slots.
-
Drawing from existing HPE server parts and know-how was a given — HPE sells hundreds of thousands of servers each quarter after all. Storage controllers (even if you add up all storage vendors together) are a tiny fraction of that number. Taking advantage of server economies of scale was a no-brainer.
Also consider some of the other benefits of a common hardware platform:
-
Easier logistics with single hardware field training
-
Easier, faster development
-
Easier, more consistent installations
-
Easier supportability and distribution
-
Lower inventory costs and easier parts stocking
-
Easier to develop automation for anything from the management plane to much more complex automation
-
Lower costs due to economies of scale
-
Resistance to supply chain issues
The building blocks of HPE Alletra Storage MP
The various HPE Alletra Storage MP building blocks allow multiple kinds of architectures to be built. At a basic level, there are just two items: a chassis and (optionally) dedicated cluster switches. The chassis can become just compute, or compute with storage. After that, things can be combined as needed.
For example, the JBOF (Just a Bunch of Flash) expansion shelf is itself built like a complete standalone system: in the HPE Alletra Storage MP chassis, it has storage media and two “controllers”, each with an OS, RAM, and CPU. The expansion slots, CPUs, and memory used are minimal but enough to satisfy full-speed JBOF duties.
Storage media is flexible – SSDs, SCM, and NVDIMMs are all currently supported. So perhaps not “just” a bunch of flash, but the JBOF name is here to stay.
Increase the JBOF compute power and expansion slots, and now you can use that same architecture as a compact storage array with two controllers and storage inside the same HPE Alletra Storage MP chassis. For bigger capacity and performance needs, a disaggregated architecture can be used, connecting diskless compute to JBOFs in large clusters.
The new HPE GreenLake for File Storage offering is essentially this last combination— a disaggregated, shared-everything (DASE) cluster using diskless compute nodes, 100Gb RDMA networking, and JBOFs to create a complete solution.
The expanded HPE GreenLake for Block Storage offering, on the other hand, starts as a smaller, stand-alone switchless system, with subsequent iterations adopting the same disaggregated paradigm to build much larger solutions.
The following figure should make it all very clear:
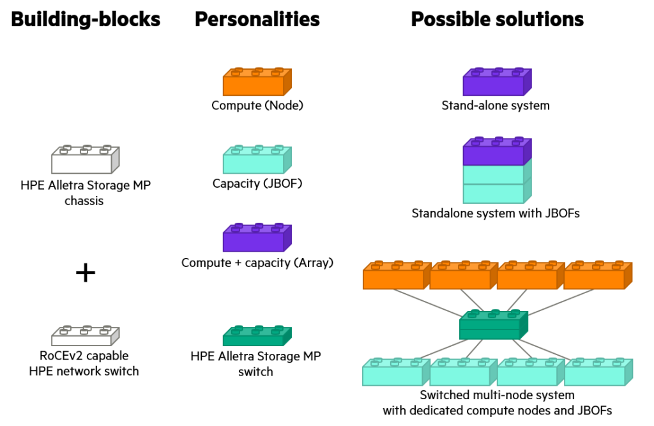
HPE Alletra Storage MP Building Blocks
For those who love looking at boxes, here’s a photo of one of the new systems.

Bezel designers are the unsung heroes of storage. Without them everything would look the same.
The new HPE GreenLake for Block Storage – powered by HPE Alletra Storage MP
Now that we’ve explained the basic HPE Alletra Storage MP hardware architecture details, what’s the new block storage offering from HPE? It’s the next evolution of the HPE block protocol storage, combining novel approaches with certain tried-and-true elements and concepts from our existing systems.
Current challenges you face
To date, if you want more capacity – you simply add more storage. That’s easy with most storage solutions. But what if you only wanted more performance and your media wasn’t performance-saturated? In this scenario, the typical storage industry option would be to replace your current controllers with faster ones.
What if your performance needs exceed what a couple of controllers can do? Traditionally, you’d have to buy a whole new system, even if you didn’t need more capacity (the classic “orphan capacity” problem). Or, in the cases of “high-end” monolithic storage, you’d be able to have more than two, still identical controllers – yet not be able to have any flexibility, dissimilar controllers, odd numbers of controllers, etc. And in most cases you’d still need to add more capacity along with the extra controllers.
What about software-defined storage? That’s typically not disaggregated, but in fact closer to how most HCI works. Each server owns storage, so there’s no good way to grow capacity or performance separately, and, if you lose a node, you also lose storage, which is not the fault domain behavior we want. With the new systems, HPE tackled this problem, plus several more.
What’s being carried over from before?
We retained the advanced, user-facing data services and APIs of the HPE 3PAR/HPE Primera/HPE Alletra 9000 line in the new expanded HPE GreenLake for Block Storage. So, things like Active-Active access to sync replicated volumes from both sites will be available (Active Peer Persistence). Migrations from older systems – such as HPE 3PAR Storage - will be easy and non-disruptive. And you’ll have conveniences like being able to granularly add capacity in two-drive increments and being able to be in a Peer Persistence relationship with an older system.
Some other concepts (no porting though as this was all new code), like significantly enhanced compression heuristics and redirect-on write snaps, were carried over from HPE Nimble Storage. Other techniques, like always doing full stripe writes and extremely advanced checksums that protect against lost writes, misplaced writes, and misdirected reads, were carried over as well.
Across all of it, you get centralized management of all devices from HPE GreenLake Data Services Cloud Console, a 100% data availability guarantee, and HPE’s unconditional satisfaction guarantee.
What’s new? A lot more flexibility and resilience
A key design principle for all the HPE Alletra Storage MP personas was to provide the option of disaggregated growth and fault domain management for everything. What if you could add performance as needed, without worrying about capacity? What if you wanted to just add a single extra node? Maybe to have just a bit more speed, or perhaps to set it aside so you could have the same performance headroom even if you lost a node? What if you wanted to be able to withstand the simultaneous loss of multiple nodes in the cluster? What if you could grow by adding dissimilar nodes instead of being forced into the exact same type all the time?
With the HPE Alletra Storage MP architecture, you can do all that. But we didn’t stop there.
Most (probably all) other systems need to have some sort of write cache and must maintain the coherence of that write cache between at least two controllers, even in 4+ controller monolithic arrays. The write cache needs to be protected in case of node or power failures, and different techniques are used for this in the storage industry, like batteries or supercapacitors.
You can also lose write speed since that write cache has to be replicated between nodes before being committed to stable media. Sure, the cache mirroring happens at the throughput speeds of some sort of fast interconnect, but at scale, this adds up and creates other issues. Surviving simultaneous node failures also becomes a challenge with such mirrored write cache schemes — what if you lose the wrong two nodes at the same time?
So, we developed technology to get rid of all these limitations. For starters, we don’t waste time mirroring write cache between nodes. In fact, we don’t even have a volatile write cache as such, and therefore have no need for batteries or supercapacitors to protect that which does not exist.
Instead, we use an intelligent write-through mechanism directly to media. Writes use a write-through model where dirty write data and associated metadata is hardened to stable storage before an I/O complete is sent to the host. The amount of hardening depends on how critical the data is, with more critical data having more copies. The architecture is flexible and allows for that “write cache” storage to be a special part of the drives, or different media altogether. An extra copy is kept in the RAM of the controllers for even more hardening and acceleration.
Each volume ends up getting its own intent log this way, which is a departure from other storage systems that tend to have a centralized cache to send writes to. This way of protecting writes also allows more predictable performance on a node failure, simpler and easier recovery, completely stateless nodes, the ability to recover from a multi-node failure, plus easy access to the same data by far more than two nodes.
Eventually, the writes are coalesced, deduped and compressed, and laid down in always-full stripes (no overwrites means no read-modify-write RAID operations) to parity-protected stable storage.
Snapshots use a relocate on write mechanism, which means there is no snapshot performance penalty even with heavy writes.
We’re just getting started
The initial release of the new expanded HPE GreenLake for Block Storage will be switchless arrays with disks inside the main chassis, and a near future update will bring the larger, switched, fully disaggregated, shared-everything architecture for much larger and more flexible implementations.
So, there you have it: The new HPE GreenLake for Block Storage, built on HPE Alletra Storage MP. A bit of old, a lot of new, and lots of benefits and flexibility.
If you want to learn more
Watch these new videos:
Back